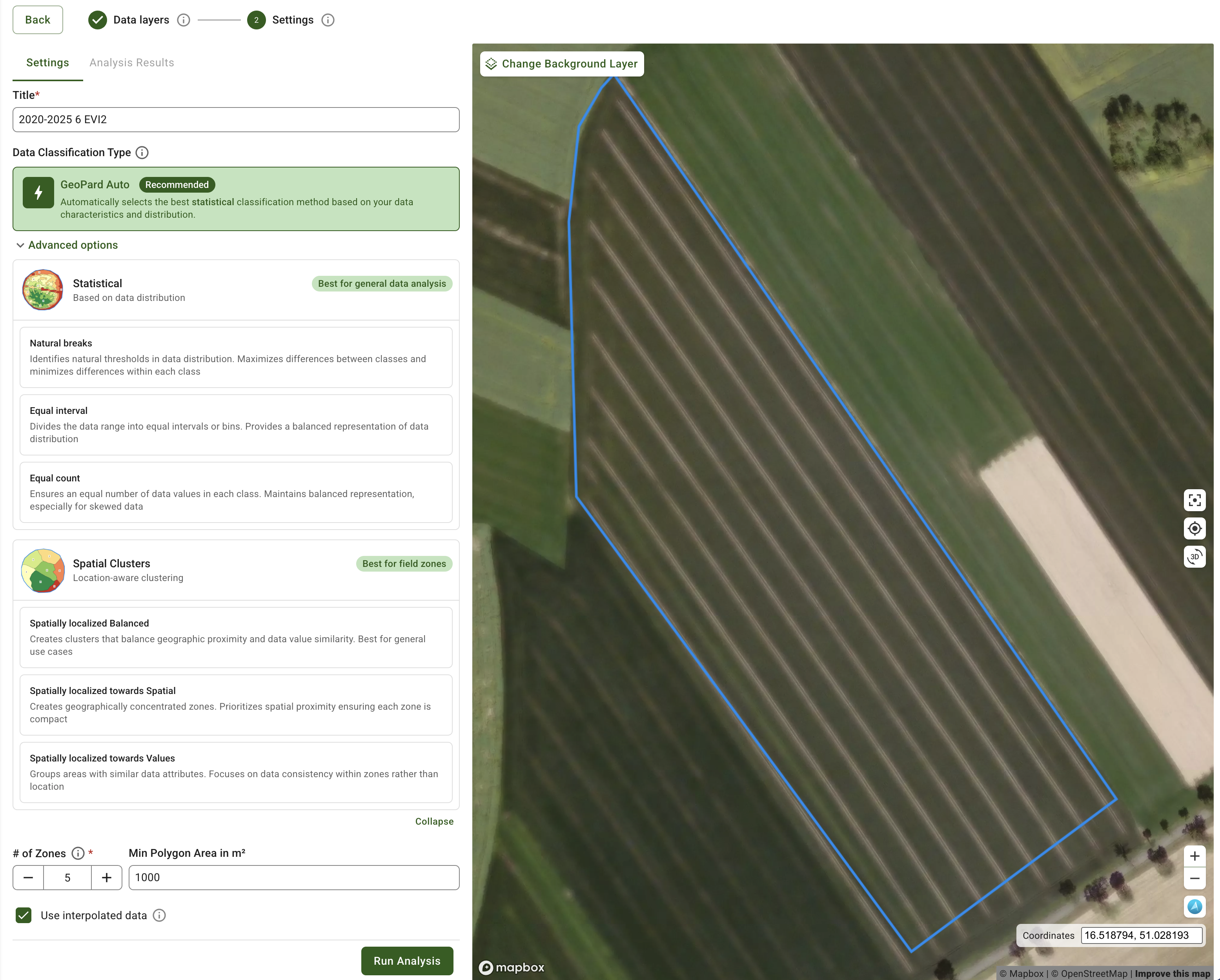
AUTO classification
AUTO classification

Natural Breaks Classification

Equal Interval Classificaiton

Equal Count (Area) Classification

Spatially Localized Classification (Balanced Option)

Spatially Localized Classification (towards Values Option)

Spatially Localized Classification (towards Spatial Option)